
Technical notes
Methodology
Given Assumption 1 and Approximation 1, the proportion of clients who have at least 1 service record with a valid SLK is:
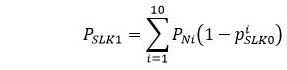
Now:
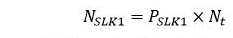
so it follows that the total number of clients is:
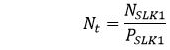
To resolve this equation for Nt the values of PNi is required. These are unknown, given it is not possible to observe the whole population due to the records with invalid SLK values. This method imputes the unknown PNi using numerical methods, then uses these values to impute Nt.
The process starts with the distribution of number of records per client that were observed using the records with valid SLKs (PNi,SLK1). These values are then adjusted so that the following conditions are met.
Constraint 1
The sum of the imputed proportions is equal to 1. That is:
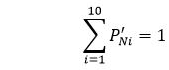
Constraint 2
The imputed proportion of clients with 1 service record is less than or equal to the observed equivalent proportion among clients with records with valid SLKs. That is:
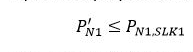
This constraint is used because some of the clients observed to have only 1 record will, in fact, have additional records with invalid SLKs. It is unlikely that the true proportion of clients with 1 service record is higher than that observed using records with valid SLKs.
Constraint 3
The total number of service records that the imputed total number of clients and the imputed distribution of records per client imply is equal to the observed number of service records.
That is:
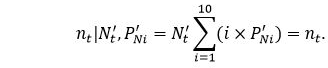
This constraint is used to ensure that the imputed values are consistent with the observed number of records.
Penalty function
Under Assumption 2 we want to limit how much the imputed proportions differ from the proportions observed via the records with valid SLK data. To achieve this we use a penalty function that increases as the distance between the imputed and observed proportions increases. this function is defined to be:
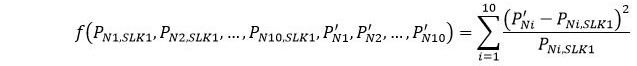
Using numerical methods, the P'N1, P'N2, ... P'N10 are chosen that the penalty function is minimised, subject to the 3 constraints.
The final step is to use the imputed proportions to calculate the imputed total number of clients:
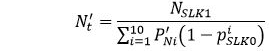
The resulting number is then rounded to the nearest integer.
Discussion
This imputation technique uses available information to impute the total number of clients. The methodology takes into account the proportion of records with invalid SLK data and the distribution of the number of service records per client, as observed via the records with valid SLK data. It is apparent that the assumptions made do not hold for every client or service record. It is reasonable to expect that a client’s attendance at a service provider will be affected by location and any prior contact they had with a provider. It should also be noted that some service providers failed to collect SLK for any service record during the reference period.
Despite the known cases where Assumption 1 does not hold, it is reasonable to hope that, across the population as a whole, the assumption is a reasonable representation of the populations of clients and service records.
It is believed that the impact of Approximation 1 will be small because, given Assumption 1, the chance that a client with more than 10 service records is not observed via a record with a valid SLK is extremely small. The chance diminishes as the proportion of records with an invalid SLK decreases and across jurisdictions the highest proportion observed is about 0.3. It should also be noted that the largest proportion of clients with 10 or more service records observed in the data at the jurisdiction level was only 0.007.
There are many different penalty functions that could be used in this imputation. The function used was chosen because, compared with the other penalty functions investigated, it produced imputed proportions that were generally as close or closer to the observed proportions. It also most consistently resulted in a distribution that was similar in shape to the observed distribution of the number of records per client.